封面 PID:78511633
杂项
数据库四个基本概念:数据、数据库(长期、有组织、可共享数据集合)、数据库管理系统、数据库系统(结构化、高共享低冗余、独立性、统一管理控制)
数据管理发展:人工管理——文件系统——数据库系统
两类数据模型:概念模型、逻辑模型和物理模型
数据模型组成:数据结构、数据操作、数据完整性约束
- 模式:全体数据的逻辑结构和特征的描述,中间层上下无关
- 外模式:局部数据的逻辑结构和特征的描述,模式子集,屏蔽下层
- 内模式:数据物理结构和存储方式的描述
关系数据库
候选码:唯一的标识一个元组(一行)的最小属性组。如果该属性组包含了所有属性则称为全码
主属性:候选码的各属性,
主码:从候选码中选一个出来
关系的三类完整性:实体完整性(主键不重复)、参照完整性(外键引用)、用户自定义完整性
五种基本关系操作(这里把关系当作一个表,属性为列,元组为行):
- 选择σ:从表中选出符合条件的行,如$\sigma _{c>1}(R)$
- 投影$\Pi$:提取表的若干列出来,如$\Pi_{Sno,Sdept}(Student)$
- 并∪:要求双方列结构相同;两表垂直方向上拼接并去重
- 差—:要求双方列结构相同;被减表有的而减表没有的行
- 笛卡儿积×:$R\times S={\overset{\frown}{t_rt_s}|t_r\in R\wedge t_s\in S}$,两表列扩展,行自由组合
给定关系 R(X,Z) ,X和Z为属性组。当t[X]=x时,x在R的象集定义为$Z_x={t[Z]|t\in R,t[X]=x}$(即符合“某些属性等于x”的行,提取他们的其他列)
扩展关系操作:
- 连接$\bowtie$,N对属性符合某个条件的行水平拼接
- 自然连接:若干对属性相等,并且消除重复列
- 等值连接:指定某对属性相等,不消除重复列
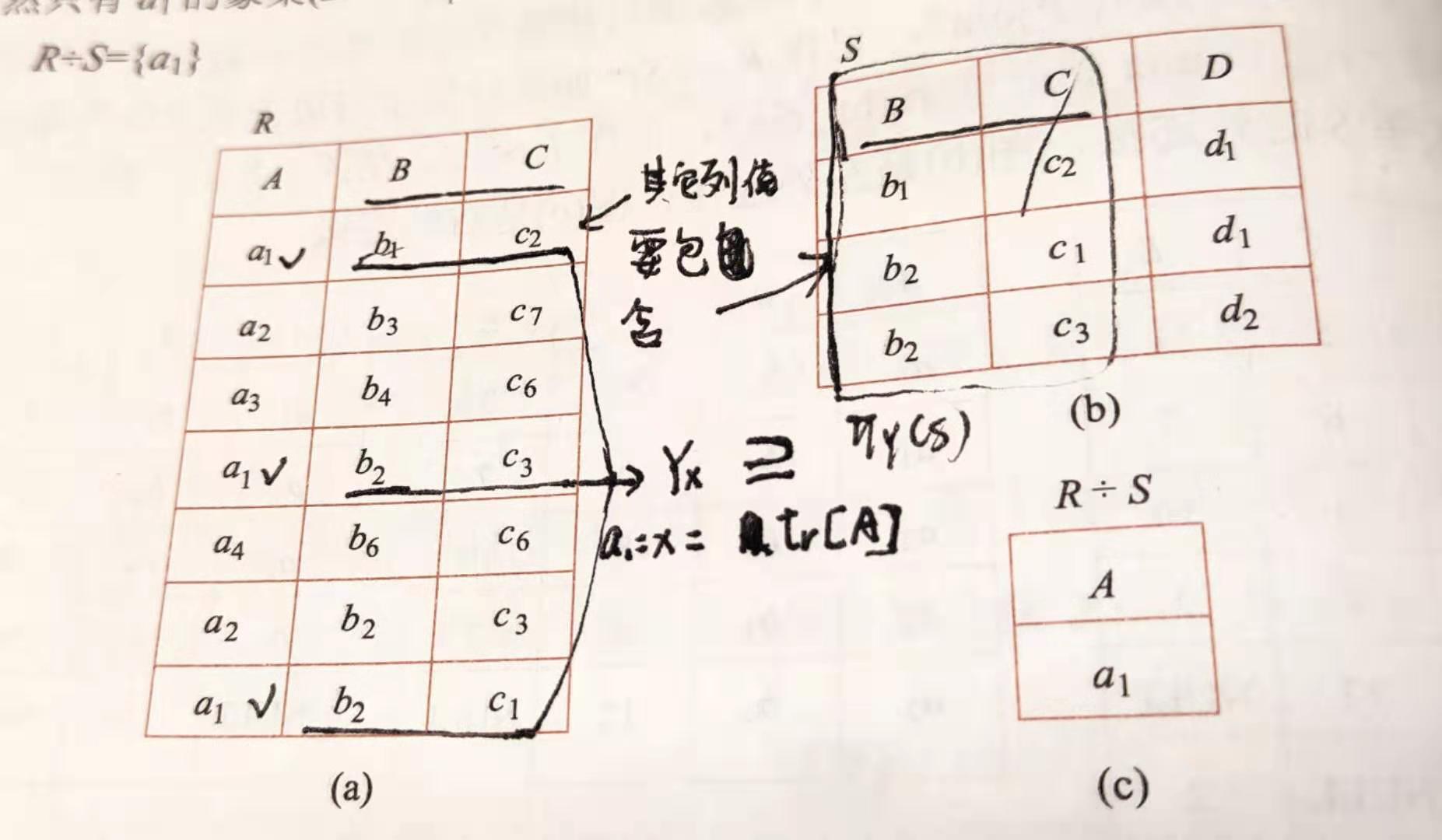
- 除法$\div$:给定 R(X,Y) 和 S(Y,Z),Y是共有属性组,有$R\div S={t_r[X]|t_r\in R\wedge\Pi_Y(S)\subseteq Y_x}$,其中 Y
x为 x 在 R 中的象集,x=tr[X]。 - 一个除法的例子如下,通常用于表示“至少包含”的意思
安全性&完整性
安全性主要有:用户身份鉴别(最外层保护)、存取控制(自主/强制)、审计、视图、数据加密等
自主存取控制中的授权
grant <权限> --如 insert/delete(sno)/all privileges 等
on <对象类型> <对象名> --如 on table Student
to <用户> --某个用户或public
[with grant option] --表示权限是否能传播权限回收
revoke <权限>
on <对象类型> <对象名>
from <用户>
[cascade/restrict] --是否级联回收在强制存取控制中,主体(用户和进程)和客体(表视图等)被赋予等级
- 仅当主体的许可证级别大于或等于客体的密级时,该主体才能读取相应的客体
- 仅当主体的许可证级别等于客体的密级时,该主体才能写相应的客体
审计是指把所有对数据库的操作记录在日志中,以便事后分析。分用户/系统级审计
数据库的完整性指数据的正确性和相容性
- 实体完整性:主键非空唯一。检验唯一的方法有全表扫描或使用索引
- 参照完整性:外键关系引用正确。在建表最后使用
foreign key(sno) references Student(sno)定义。- 修改参照表破坏完整性:拒绝
- 修改被参照表破坏完整性:拒绝/级联更新删除/置空
- 用户定义完整性:基础sql略
关系数据理论
完全函数依赖:$X\stackrel{F}{\rightarrow}Y$,X除了本身没有子集能决定Y(X已经是最小)
部分函数依赖:$X\stackrel{P}{\rightarrow}Y$,X有子集能决定Y
传递函数依赖:$X\rightarrow Y\rightarrow Z$,称$X\stackrel{pass}{\rightarrow}Y$
候选码能唯一确定一行(所有属性完全函数依赖于候选码),包含候选码的属集叫超码(所有属性部分函数依赖与超码)
范式
- 1NF:各属性不可再分
- 2NF:1NF 的前提下,每一个非主属性完全函数依赖于码(没有部分依赖)
- 3NF:2NF 的前提下,每一个非主属性不传递依赖于码(没有传递依赖)
- BCNF:3NF 的前提下,每一个决定因素(箭头左边)都包含码
Armstrong公理系统推理规则:
- 合并规则:$X\rightarrow Y,X\rightarrow Z$,有$X\rightarrow YZ$
- 伪传递规则:$X\rightarrow Y,WY\rightarrow Z$,有$XW\rightarrow Z$
- 分解规则:$X\rightarrow Y,Z\subseteq Y$,有$X\rightarrow Z$
属性集X关于函数依赖集F的闭包$X^+_F$,也就是 X 能在 F 下能决定的属性的集合。算法如下
- X和X的子集都可作为决定因素,这些决定因素都可以利用 F 推出结果 Result
- 把 Result 并在 X 上更新 X,重复以上操作直到 X 不再变化或者 X 等于全集,这时的 X 即为解
- 一个例子如下

函数依赖集 F 的极小化(获取最小覆盖):
- 从 F 中取一个$X\rightarrow Y$出来,剩下$G=F-{X\rightarrow Y}$
- 如果 X 能在 G 下推出 Y,从 F 中删除$X\rightarrow Y$(多余),重复以上操作直到 F 中的每个函数都被操作了一遍
求码算法:
- 只出现在箭头左边/两边都不出现的肯定是码的一部分
- 只出现在箭头右边的肯定不是码的一部分
- 两边都出现的,如果不能被只出现在箭头左边的推出,是码的一部分
分解的无损连接性判断:设分解后两关系模式的属性集分别是 U1 和 U2,满足$U_1\cap U_2\rightarrow U_1-U_2\in F^+$ 或 $U_1\cap U_2\rightarrow U_2-U_1\in F^+$
将模式分解成 3NF 并保持函数依赖的算法
- F 极小化处理,仍记为 F
- 不在 F 中出现的属性集合 U
0构成一个关系模式 R(U0,F0)。U 去掉 U0仍记为 U - 若 F 中存在“某些属性决定剩下的属性”,算法结束,不用分解
- 否则对 F 按具有相同的左部原则分组,k 个分组的左部构成 k 个属性集,去掉其中的 U
i($U_i\subseteq U_j$)剩下 k' 个属性集,这 k' 个属性集和 U0构成分解
数据库设计
数据库设计分六步骤
- 需求分析:明确需求,建立数据字典(数据项、数据结构、数据流、数据存储、处理过程)
- 概念结构设计:反映真实世界的模型;ER图中的属性/命名/结构冲突
- 逻辑结构设计:将概念模型转换为符合 DBMS 数据模型的逻辑结构,设计用户子模式
- 物理结构设计:存取方法和存储结构的选择
- 数据库实施
- 运行和维护
查询优化
RDBMS查询处理阶段:查询分析、查询检查、查询优化
选择操作实现:全表扫描和索引扫描
连接操作实现:嵌套循环、排序合并、索引连接、hash连接
代数优化:选择优先(选择后移)、投影和选择同时进行、投影分配、连接代替笛卡尔
物理优化:基于规则的启发式优化、基于代价估算的优化
数据库恢复
事务:不可分割的操作序列,只能全做或全不做,是恢复和并发控制的基本单位
事务的 ACID 四特性:
- 原子性:全做或全不做
- 一致性:不能出现不一致状态(原子性)
- 隔离性:各事务间不干扰
- 持续性:事务一旦提交改变就是永久的
故障类型:
- 事务故障;通过撤销事务恢复
- 系统故障(软故障);撤销未提交事务,重做已提交的事务
- 介质故障(硬故障);使用镜像或备份恢复
恢复技术:
- 数据转储,建立备份供恢复
- 静态转储:转储时无法操作存取修改,保证一致性但是降低可用性
- 动态转储:与静态相反(但是可以加入日志文件解决)
- 海量转储:转储所有数据
- 增量转储:只转储新更新的数据
- 登记日志文件,记录更新操作以供恢复
恢复策略:
- 对事务故障:系统自动进行,反向扫描日志逆向操作
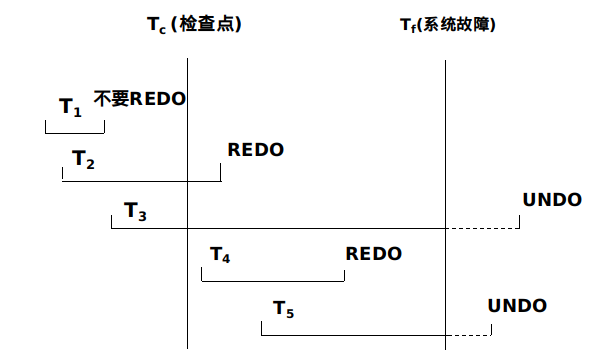
- 对系统故障:正向扫描获得故障前已完成和未完成的事务,分别对他们进行重做和撤销
- 对介质故障:备份恢复后使用日志恢复
检查点技术:
- <u>在日志文件中增加检查点记录,检查点由正在执行的事务及其指向地址组成</u>
- <u>重新开始文件记录各检查点在日志文件中的位置</u>
并发控制
并发操作带来的不一致性/破坏隔离性:
- 丢失修改:别人还没保存结果就读取用来修改了
- 不可重复读:因为其他事务的干扰,本事务前后读取的同一数据发生变化
- 读脏数据:读了别人修改的数据,但别人撤回了
排他锁/X锁:加上之后不允许其他人读写被锁数据,也不允许其他人加锁
共享锁/S锁:加上之后只允许读,只允许其他人加S锁
封锁协议
- 一级封锁协议:修改数据前加X锁,事务结束才释放。能防止丢失修改
- 二级封锁协议:一级封锁下,读取数据前加S锁,读完后释放。能防止丢失修改和读脏数据
- 三级封锁协议:一级封锁下,读取数据前加S锁,事务结束才释放。能解决三个问题
活锁就是抢占造成饥饿(先来先服务解决),死锁就是资源的相互等待(一次封锁、顺序封锁预防、打破循环解除)
可串行化调度:指事务并发执行的结果与按某一次序串行地执行这些事务时的结果相同(定义)
冲突:指不同事务对同一个数据至少包含一读的操作
优先图构造(如果优先图有回路,不可串行化):
- 节点为事务
- 当 R
i(x)在Wj(x)前、 Wi(x)在Rj(x)前、Wi(x)在Wj(x)前,加入一条 i 到 j 的有向边
使用两段锁协议(操作之前要加锁,解锁之后不能加锁)能保证可串行化调度,但是不能排除死锁
封锁粒度越大,并发度和开销越低,反之亦反。
多粒度封锁具有向下传递性,上层节点被加锁(显式封锁),其子节点也相当于被加上同类锁(隐式封锁)
对于修改操作,需要检测当前及父辈节点是否存在冲突;对于加锁,需要检测当前及父子节点是否存在冲突
意向锁:若要对底层资源加锁,必须对高层资源加意向锁(被上意向锁的节点,儿子肯定被上锁了),这样在冲突检测时能免去对子节点的检测
- IS锁:对节点加IS锁,表示要对儿子节点加S锁
- IX锁:对节点加IX锁,表示要对儿子节点加X锁
- SIX锁:对节点加S锁和IX锁

Comments | ?? 条评论